
1. 배열(Array)의 개념
1.1 배열이란?

우리가 흔히 생각하는 배열의 개념은 자료를 선형적으로 모은 자료구조입니다. 실제로 배열은 선형 자료구조의 한 종류이긴 합니다. 하지만, 컴퓨터 공학에서 배열은 몇 가지 추가적인 특징을 가지고 있습니다.
In computer science, an array is a data structure consisting of a collection of elements (values or variables), of same memory size, each identified by at least one array index or key.
- Contiguous : 배열의 각 요소는 메모리 공간에서 인접한 곳에 위치하고 있습니다.
- Fixed Size : 배열 요소의 개수(크기)는 사전에 정의된 대로 고정되어 있습니다.
- Constant Access Time : 배열의 각 요소에 접근하는 시간은 배열의 크기와 상관없이 항상 일정합니다.
- Same Data Type : 메모리의 크기가 같은 종류의 데이터들의 모음입니다.
위의 특징을 보면 배열은 각 요소에 접근하고 값을 참조하는 것에는 유리하지만, 크기가 고정되어 있기 때문에 요소를 추가하거나 삭제 시 불리한 것을 알 수 있습니다. 결국 배열은 자료를 선형적으로 보관하고 자료를 추가하거나 삭제하지 않고 검색을 위주로 할 때 사용하면 매우 좋은 자료구조입니다.
그럼 왜 배열은 접근 시간은 빠를까요?
1.2 배열의 인덱스
배열의 각 요소는 인덱스(index)를 통해 접근합니다. 인덱스는 각 요소가 배열에 몇 번째 위치한 것인지를 나타내는 수입니다. 컴퓨터 내부에서는 사실 배열의 모든 요소의 메모리 주소를 저장하지 않습니다.
배열의 첫 번째 요소의 주소값과 인덱스를 통해 접근하고자 하는 요소의 주소값을 알아낼 수 있죠.

예를 들어 위 그림 배열의 3번째 요소의 주소값을 알고 싶으면 (첫 번째 주소값 + 데이터 사이즈 x 인덱스)를 계산하기만 하면 됩니다. 이렇게 메모리 주소를 계산하는 작업은 하나의 명령어로도 가능하기 때문에 매우 빠른 편입니다.
1.3 배열에 요소를 추가하는 것과 삭제하는 것은 왜 느릴까?
배열의 요소들은 반드시 인접한 메모리 공간에 위치하고 있어야 합니다. 따라서 추가와 삭제 시 추가적인 동작이 필요합니다. 그림을 보면 확실히 이해가 갈 것 같습니다.

만약 배열 중간에 새로운 요소를 추가한다고 하면 어떻게 될까요? 추가할 위치보다 뒤에 있는 요소들을 한 칸씩 이동시켜야 합니다. 만약 배열의 크기가 매우 크다고 가정하면 이렇게 요소를 추가하는 것은 상당히 오래 걸릴 것입니다. 삭제도 마찬가지입니다.

2. Java에서 배열의 사용
2.1 배열의 선언
Java에서 배열은 참조(Referece)타입입니다. 따라서 배열을 사용하기 위해선 참조변수의 선언과 메모리 할당 두 가지 동작이 필요합니다.
먼저 배열의 참조 변수를 선언하는 방법은 다음과 같습니다.
int[] arr1; // 관례상 주로 이 방법을 사용한다.
int arr2[];이렇게 참조변수만 선언하면 배열을 사용하지 못합니다. 선언한 배열을 사용하기 위해선 반드시 데이터를 저장할 메모리 공간을 할당해야 합니다.

2.2 배열의 초기화
배열을 초기화하는 방법은 크게 2가지가 있습니다.
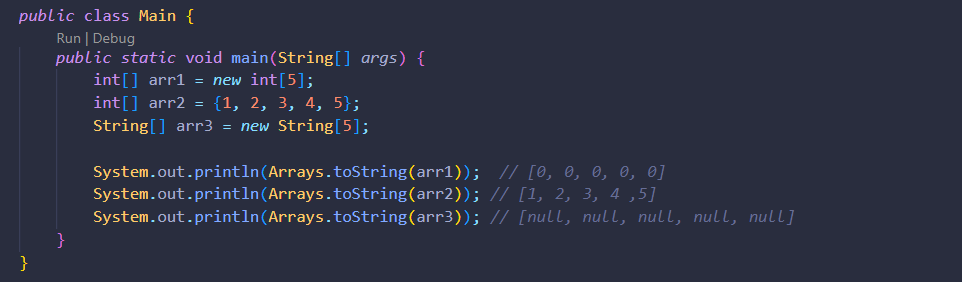
int[] arr1 = new int[5];
int[] arr2 = {1, 2, 3, 4, 5};new 연산자를 사용하여 초기화하는 방법과 { } 안에 실제 데이터를 기입하여 초기화하는 방법이 있습니다. 만약 { }을 사용하여 초기화하면 기입한 요소의 개수만큼 배열의 크기가 정해집니다.
만약 new 연산자를 통해 배열을 초기화하면 모든 요소의 초기값은 int의 경우 0이 되고 String의 경우에는 null값입니다.
for문을 통해 배열의 요소를 초기화할 수 있습니다.

for문을 통해 배열의 인덱스 i값을 증가시키면서 배열의 요소를 초기화했습니다. 이때 for문의 조건문을 자세히 보시면 arr1.length 변수를 볼 수 있습니다.
Java에선 배열의 길이를 잘못 계산하는 것을 방지하기 위해 length라는 변수를 제공합니다. 이는 배열의 길이를 나타내는 변수입니다.
3. 기본타입 & 참조 타입 배열
3.1 기본 타입(Primitive Type) 배열
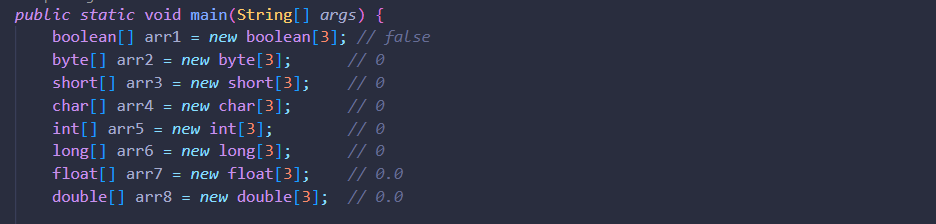
배열은 기본타입을 저장할 수 있습니다. 총 8가지의 기본타입의 배열을 모두 지원합니다. 해당 기본 타입 배열을 new 연산을 통해 초기화하면 다음과 같은 기본값을 가집니다.
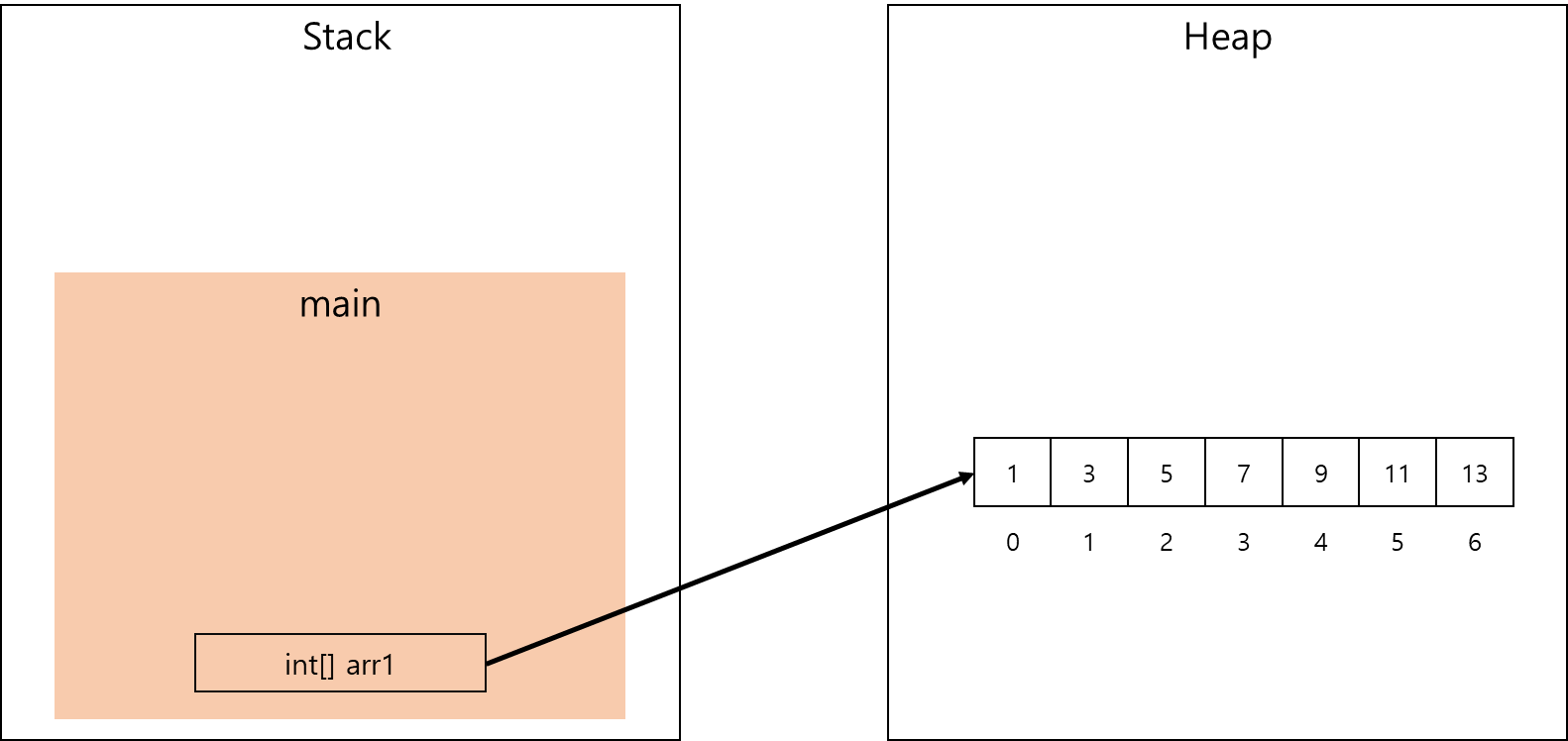
기본 타입 배열은 메모리 공간에서 아래의 그림과 같이 저장됩니다.
3.2 참조 타입(Reference Type) 배열
배열은 같은 데이터형끼리만 저장하면 되기 때문에 Java에서는 객체들이 요소인 참조타입 배열도 있습니다.

다음과 같이 객체 배열을 선언하고 해당 배열에 객체를 할당하고 출력해 보니 다음과 같은 결과를 얻었습니다.

3.3 참조 타입 배열의 복사
기본타입 배열의 경우 clone() 메소드를 통해 배열을 복사할 수 있습니다.

참조 타입의 배열의 경우에도 clone()을 하면 복사를 할 수 있지만, 조심해야 할 점이 있습니다.

arr1의 출력값과 arr2의 출력값을 자세히 보면 복사된 값이 Shape의 멤버변수의 값이 복사된 것이 아니라 단순히 객체의 참조변수 값이 복사된 것을 볼 수 있습니다.

위의 메모리 구조를 보면 두 개의 배열의 각 요소들이 같은 객체를 가리키는 것을 볼 수 있습니다. 이때 발생하는 문제점은 예를 들어 arr1의 어떤 요소를 변경하면 arr2도 같이 복사된다는 것입니다.

따라서 참조 배열의 주소값을 복사하는 것이 아니라 객체의 값을 전부 복사하는 깊은 복사를 하고 싶으면 for문을 이용해서 직접 복사해야 합니다.

4. 다차원 배열
4.1 다차원 배열이란?
다차원 배열은 배열의 차원이 2차원 이상인 배열을 의미합니다. 다차원 배열은 배열로 배열의 구조로 구성된 배열입니다. 즉, 배열의 요소가 다시 배열인 것을 의미합니다.
예를 들어 2차원 배열의 요소는 1차원 배열이며 1차원 배열의 요소는 데이터가 되는 구조입니다.

2차원 배열은 행과 열로 구성된 테이블이라고도 할 수 있고 3차원 배열은 행, 열, 깊이로 구성된 큐브형태라고 할 수 있습니다. 메모리 공간이 여유롭다면 배열의 깊이를 무한히 늘릴 수는 있지만, 주로 3차원 이하의 배열만 사용합니다.
4.2 2차원 배열의 선언 및 초기화
int[][] arr1 = new int[2][3]; // [행][열]
int[][] arr2 = {{1, 2, 3}, {4, 5, 6}};2차원 배열도 new 연산자를 사용하거나 {}를 이용하여 선언 및 초기화를 동시에 진행할 수 있습니다. new로 생성 시 첫 번째 [] 안에는 행의 개수 두 번째 [] 안에는 열의 개수를 넣어줘야 합니다. arr1의 경우 2x3의 테이블이라고 생각할 수 있습니다.
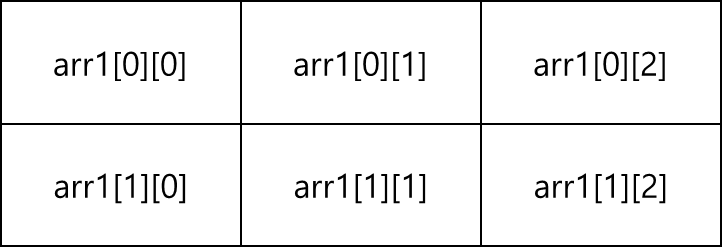
4.3 2차원 배열의 순회

2차원 배열도 1차원 배열과 마찬가지로 반복문을 통해 각 배열의 요소에 접근할 수 있습니다. 다만 차이점은 2차원 배열은 for문을 2번 중첩해야 순회를 할 수 있습니다.
2차원 배열의 범위를 정할 때도 length 변수를 사용할 수 있는데 이때 사용 방법이 약간 다릅니다. 먼저 arr.length를 사용하여 행의 개수를 구하고 안쪽 for문에서는 arr[i].length를 이용해서 i번째 행의 길이를 구했습니다.
4.4 가변 배열
자바에서는 마지막 차원의 배열은 각각의 길이가 다르게 지정할 수 있습니다. 배열의 요소는 같은 데이터형이기만 하면 되기 때문에 마지막 차원의 배열의 길이는 위 차원의 배열 데이터형에 관여하지 않기 때문에 다를 수 있습니다.
이러한 배열을 가변 배열이라고 합니다.

가변배열을 초기화하는 방법도 2가지입니다.
